
 简体中文
简体中文Set




Set是不含重复元素的集,严格来讲,Set不允许当e1.equals(e2)为真时, e1 和 e2 同时出现在集合中。Set最多允许一个null元素。
将可变对象置入Set时需要特别小心,当对象的改动影响到了元素之间的equals()比较的结果,那么Set的行为就变得不确定了。因此,不能将Set本身作为Set的元素。
散列集 #
⚠️关于散列的桶与桶中的元素,还有部分描述可能存在问题。
数组和链表能够记录元素的插入顺序,这对于通过索引快速对元素执行操作很有利,但是如果忘记了索引,那么需要从头遍历,这在数据量很大的情况下效率低下。在不考虑元素的顺序情况下,能提供快速查询所需要的数据,这就是散列表(hash table)。
散列表为每个对象计算一个整数,称为散列码( hash code ),这意味着如果将自定义对象作为Set的对象,那么必须要负责实现这个类的 hashCode 方法,还有一点要注意的是,hashCode和equals方法之间存在约束关系?,因此最好也重写equals方法以保证一致性。
Java中的散列表是用链表数组实现的,每个链表称为桶。
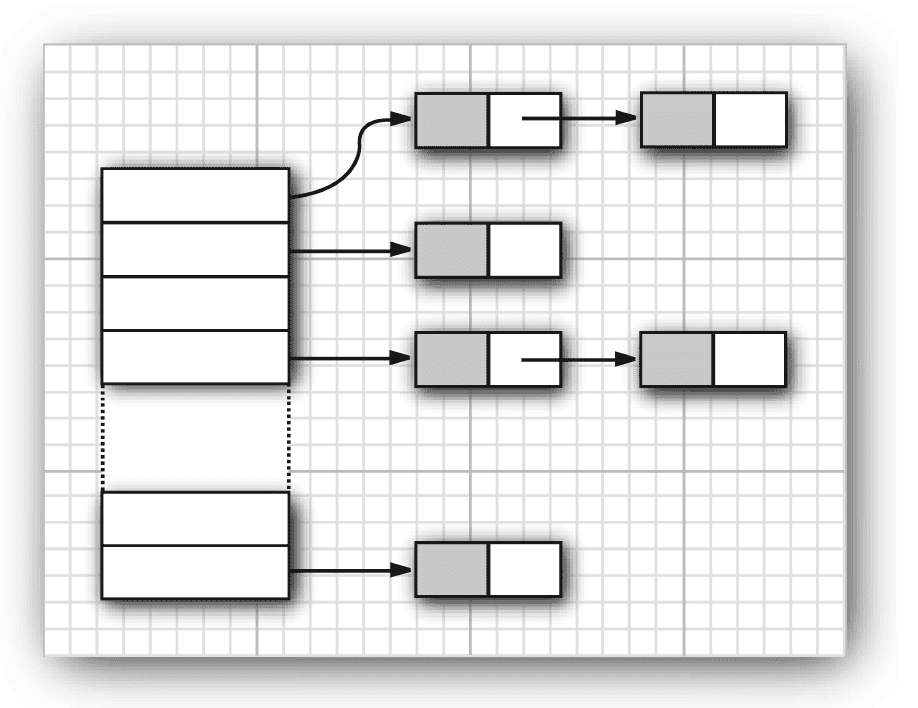
散列表(hash table) form Core Java
设有散列表桶数为 x ,有对象 y ,那么散列表如何存入对象呢?
\[ z = hash(y) \% x \]那么对象 y 应该放在 z 号桶中。
若桶被占满1了,就会发生散列冲突(hash collection),散列表会尽量避免散列冲突。
在Java 8 中,桶满时链表会转换成为平衡二叉树。
保证散列中桶数富余能够有效提升散列表的性能,反之若要插入的元素过多,散列表的性能就会降低。
散列表一般可初始化桶数,通常将桶数设置为容量的75%~150%。若不知道元素的个数,散列表太满就会导致再散列( rehashed ),在散列就是创建一个桶数更多的表(加倍),将所有的元素copy到新表,丢弃原来的表。在散列由桶数和**装填因子( load factor )**两方面决定,如果不加指定,装填因子默认为0.75,若
$$ 散列元素数 > 桶数 * 装填因子 $$
就会发生再散列
Java标准类库中,散列表的桶数总是2n,默认值是16。
HashSet #
HashSet是由HashMap实现的基于散列表的集合,允许至多一个null元素。
不论桶数,当元素被合理地分配在散列表的桶中时,HashSet的基本操作(add,remove,contains和size)的效率是一致的;但是迭代HashSet所需要的时间则与元素数量以及组成集的HashMap桶数正相关。因此合理的设置桶数非常有必要。
与List不同的是,HashSet的迭代器不能保证元素的迭代顺序,并且迭代器也是 fail-fast 的,在使用迭代器时同样需要留意 ConcurrentModificationException。
HashSet主要字段:
1 private transient HashMap<E,Object> map;
2
3 // Dummy value to associate with an Object in the backing Map
4 private static final Object PRESENT = new Object();
HashSet构造器:
1 public HashSet() {map = new HashMap<>();}
2 public HashSet(Collection<? extends E> c) {...}
3 public HashSet(int initialCapacity, float loadFactor) {...}
4 public HashSet(int initialCapacity) {...}
所以HashSet就是一个所有值为PRESENT常量的 HashMap的KeySet,参考如下示例:
1static void initializationTest() throws Exception {
2 Set<Integer> hs = new HashSet<>();
3
4 hs.add(1);
5 hs.add(2);
6
7 Class<?> cls = HashSet.class;
8
9 Field fm = cls.getDeclaredField("map");
10 fm.setAccessible(true);
11 System.out.println(fm.get(hs).getClass());
12 @SuppressWarnings("unchecked")
13 HashMap<Integer, Object> o = (HashMap<Integer, Object>) fm.get(hs);
14 for (Map.Entry<Integer, Object> entry : o.entrySet()) {
15 System.out.println(entry.getKey() + ":" + entry.getValue());
16 }
17}
18/* output
19class java.util.HashMap
201:java.lang.Object@1540e19d
212:java.lang.Object@1540e19d
22*///:~
如果将自定义对象存入HashSet,必须覆盖 equals 和 hashCode 方法
LinkedHashSet #
HashSet的子类,与HashSet的 区别在于LinkedHashSet使用双端链表维护集中的元素,因此元素能够被有序迭代(迭代顺序是元素的插入顺序),当元素添加到集中时,便会并入LinkedList中。
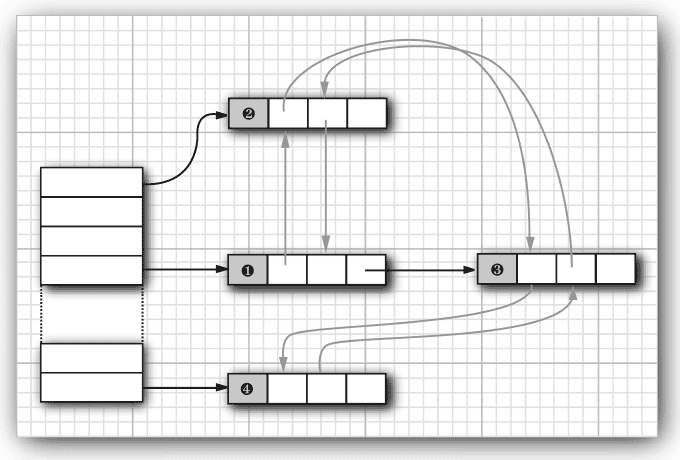
链表散列表 from Core Java
HashSet中有一个包访问权限的构造器,专门用来构造LinkedHashSet:
1HashSet(int initialCapacity, float loadFactor, boolean dummy) {
2 map = new LinkedHashMap<>(initialCapacity, loadFactor);
3}
可以看到,LinkedHashSet实质上是LinkedHashMap的是个KeySet
和HashSet的区别(性能上):
- 性能稍微比
HashSet低一点 - 由于加入了链表,迭代
LinkedHashSet时只与集合的容量(size)有关,而与桶数无关;而HashSet的迭代效率与二者都有关 LinkedHashSet设置过大的桶数所带来的性能(负)影响小于HashSet
TreeSet #
树集是由红—黑树实现的有序集合(sorted collection)。在Java集合框架中,TreeSet由TreeMap实现,和HashSet一样,TreeSet是TreeMap的所有值为new Object()的keySet。
TreeSet是NavigableSet和SortedSet的实现,其中NavigableSet接口继承了SortedSet接口
SortedSet接口定义了如下方法:
Comparator<? super E> comparator();
获取用于排序的比较器,若使用comparable则返回null
SortedSet<E> subSet(E fromElement, E toElement);
返回一个子集,元素范围从 fromElement (含)到 toElement (不含),
当 fromElement 和 toElement 相等时,返回空集,
返回的集合是一个视图,对此视图的修改会作用到原集合上,反之亦然
SortedSet<E> headSet(E toElement);
SortedSet<E> tailSet(E fromElement);
返回一个子集,元素小于/大于 toElement/fromElement ,
返回的集合是一个**视图**,对此视图的修改会作用到原集合上,反之亦然
E first();
E last();
获取集合中最小/最大的元素
NavigableSet继承了SortedSet,并新增了方法:
E lower(E e);
E higher(E e);
返回小于 *e* 的最大/大于 *e* 的 最小元素,若不存在则返回null
E floor(E e);**
E ceiling(E e);**
返回小于等于 *e* 的最大/大于等于 *e* 的 最小元素,若不存在则返回null
pollFirst();
E pollLast();
获取并删除集合中的最小/最大元素,若集合为空则返回null
Iterator<E> descendingIterator();
获取倒序迭代器
TreeSet中的元素总是有序的,排序规则可以是默认的自然排序( comparable )或在构造器中指定比较器( comparator ),和PriorityQueue一样,若向TreeSet插入未排序的元素,会抛出 ClassCastException
需要注意的是,在使用自定义比较规则时,置入TreeSet中的元素需要考虑到comparable/comparator 方法和 equals 方法的一致性
参考如下示例:
1//... 省略头部
2static void consistenceTest() {
3 class Item implements Serializable {
4 private int code;
5 private String name;
6
7 public Item(int code, String name) {
8 this.code = code;
9 this.name = name;
10 }
11
12 @Override
13 public boolean equals(Object o) {
14 if (this == o) return true;
15 if (o == null || getClass() != o.getClass()) return false;
16
17 Item item = (Item) o;
18
19 if (code != item.code) return false;
20 return Objects.equals(name, item.name);
21 }
22
23 @Override
24 public int hashCode() {
25 int result = code;
26 result = 31 * result + (name != null ? name.hashCode() : 0);
27 return result;
28 }
29 }
30 // 故意修改比较器的相等逻辑
31 SortedSet<Item> ss = new TreeSet<>((o1, o2) -> o1.code - o2.code + 1);
32 Item item = new Item(1, "apple");
33 ss.add(item);
34 ss.add(item);
35 // Set中出现重复元素
36 ss.forEach(System.out::println);
37}
38/* output:
39TreeSetTest$1Item@58b8379
40TreeSetTest$1Item@58b8379
41*///:~
上例中,对于Item对象 a 和 b ,以及Item的比较器 c ,有
a.equals(b) && c.compare(a,b)!=0
成立,那么第二次add()就会返回true,此时TreeSet中出现了重复的元素!这与Set.add方法的约束相悖,为什么?原因在于尽管Set是以equals来判断元素相等的,但是TreeSet使用的是比较器规定的方法,上例在TreeSet的角度看, a 和 b 并不等,这样会使集合出现难以理解的行为。
因此,保持比较器和equals方法的一致性是很重要的。
值得一提的是,NavigableSet的获取子集的方法,可以用来对原集合进行修改;同样地,若原集合发生改变,子集也会随之改变
这与
ArrayList的SubList不同,SubList获取子集后对原集合的修改会引发ConcurrentModificationException
1//...省略头部
2static void eleTest() {
3 TreeSet<String> ss = new TreeSet<String>() {{
4 add("nokia");
5 add("motorola");
6 add("apple");
7 add("samsung");
8 add("mi");
9 add("oppo");
10 add("vivo");
11 add("sony");
12 add("google");
13 }};
14
15 SortedSet<String> headSet = ss.headSet("oppo", false);
16 // equals
17 // SortedSet<String> headSet = ss.headSet("oppo");
18 ss.add("huawei"); // 之前的子集中也会添加
19 Iterator<String> i = headSet.iterator();
20 int j = 0;
21 while (i.hasNext()) {
22 j++;
23 i.next();
24 if (j % 2 == 0) {
25 i.remove();
26 }
27 }
28 headSet.forEach(System.out::println);
29 System.out.println("contains google? " + ss.contains("google"));
30 // 获取当前集合的逆序迭代器
31 Iterator<String> i2 = ss.descendingIterator();
32 System.out.println("vivo".equals(i2.next()));
33}
34/* output:
35apple
36huawei
37motorola
38contains google? false
39true
40*///:~
上例中,获取headSet之后对原集合添加元素,且添加的元素正好在子集的范围中 ,那么子集中也会添加这个元素;
每个桶里都有元素么?每个桶至多有多少元素?通过源码来看HashSet和HashMap一个桶里至多有一个元素 ↩︎